@FunctionalInterface // 함수형 인터페이스를 올바르게 작성했는지 컴파일러가 확인. 생략 가능
interface MyFunction{
public abstract int max(int a, int b);
}
// ---------- 구현 - 익명클래스 ----------
Myfunction f = new MyFunction(){
public int max(int a, int b){
return a > b ? a : b;
}
}
int value = f.max(3, 5);
사용 이유?
람다식을 다루기 위해서
public static void main(String[] args){
// 람다식의 참조변수를 Object로 한다면?
Object obj = (a, b) -> a > b ? a : b;
int value = obj.max(3, 5); // 람다식이 참조하는 obj에 max() 메서드가 없기 때문에 error
// --------------------------------------------------------------------------------
// 함수형 인터페이스를 참조변수로 사용
MyFunction f = new MyFunction(){
public int max(int a, int b){ // 오버라이딩 규칙 - 접근제어자는 좁게 못 바꾼다.
return a > b ? a : b;
}
}
int value = f.max(3, 5);
// --------------------------------------------------------------------------------
// 람다식으로 함수형 인터페이스 사용
MyFunction f = (a, b) -> a > b ? a : b;
int value = f.max(3, 5);
}
// 함수형 인터페이스 사용
@FunctionalInterface
interface MyFunction{
public abstract int max(int a, int b){}; // public, abstract 생략 가능
}
예제
List<String> list = Arrays.asList("abc", "aaa", "bbb", "ddd", "aaa");
// 정렬
Collections.sort(list, new Comparator<String>() {
public int compare(String s1, String s2){
return s2.compareTo(s1);
}
};
// 람다식 사용
Collections.sort(list, (s1, s2) -> s2.compareTo(s1));
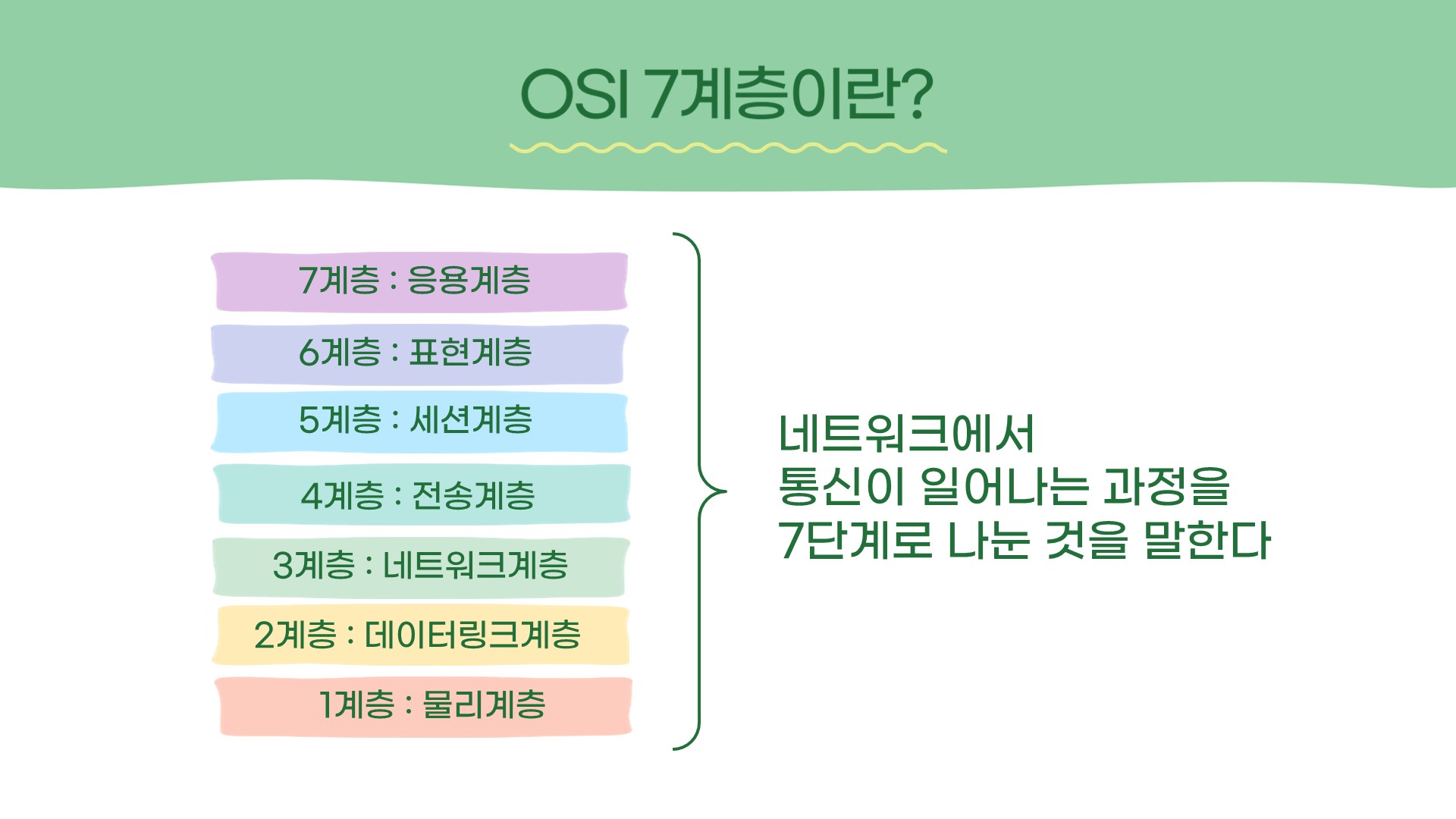
친구들과 주고받는 카톡, 아무 생각 없이 받는 다운로드 과정에서 데이터는 어떻게 움직이는 것일까?
다음의 OSI7계층을 통해 그 흐름을 파악할 수 있다.
데이터는 7계층에서 1계층까지의 과정을 거쳐 상대방의 컴퓨터에 도달하고,
다시 1계층에서 7계층까지의 과정을 거쳐 상대방에게 보여진다.
네트워크는 처음 미국 국방부 산하에서 만들어졌고(아르파넷), 국방부에서만 사용 시에는 문제가 없었다.
하지만 다른 민간 기업들이 사용하게 되고 서로 다른 네트워크를 사용하게 되면서,
서로 다른 제조사의 네트워크 장비들 간에서는 통신에 어려움이 생기었다.
따라서 표준화된 모델이 필요했고, 이에 따라 나온 것이 인터넷을 사용할 때 따라야 할 규칙이다.
OSI 7계층은 흐름을 한 눈에 알아보기 쉽게 만들어졌고,
각 계층별로 층이 나눠져 있기 때문에 한 층에 생긴 문제가 다른 층에 영향을 주지 않는다.
따라서 유지보수가 편하다는 장점이 있다.
하지만 사실 오늘날 따르고 있는 인터넷 통신 규칙은 OSI 모델이 아닌 TCP/IP 모델이다.
왜일까? 이유는 아래에...
OSI 7계층은 기술의 가용성을 고려하지 않은 이론적인 모델이기 때문에 구현에 있어 제한사항이 많다.
무엇보다 출시 시기가 TCP/IP 모델보다 늦어 이미 TCP 모델이 장악하고 있는 네트워크 시장에서 사용되기가 쉽지 않았다.그럼에도 우리는 OSI 7계층을 중요하게 배우는데 이유는 다음과 같다.
데이터의 흐름을 각 계층별로 잘 정리해 놓아 공부하기 좋고,
오늘날 네트워킹 장치를 만들 때 기본적으로 OSI 7계층을 참조해서 만들기 때문에 OSI 7계층을 배워야 한다.
기존의 OSI 모델과 TCP/IP 모델이다.
가장 오른쪽의 TCP/IP 모델이 최신 모델인데,
OSI 모델의 영향을 받은 것을 확인할 수 있다.
이제 본격적으로 데이터가 어떤 경로를 거쳐 이동하는지 알아보자.
7계층은 응용계층이라 불린다.
현재 보고 있는 웹 어플리케이션 같은, 사용자가 접근할 수 있는 가장 가까운 계층이다.
여기서 데이터 전송 등의 명령을 내린다.
대표 프로토콜로는 HTTP, SMTP 등이 있는데,
프로토콜이란 데이터를 보내기 위해 정해놓은 통신 규약이다.
우리가 보고있는 웹사이트 화면의 경우 HTTP 프로토콜을 사용한다.
SMTP는 인터넷 상에서 전자메일을 보낼 때 사용되는 프로토콜이다.
6계층은 표현 계층이라고 불리며,
응용 계층에서 내린 명령 또는 발송한 데이터를 어떻게 표현할 지 정해주는 계층이다.
즉, 인코딩을 통해 오류 없이 데이터를 주고 받을 수 있도록 표현해주는 계층이다.
그림에서 JACK_DATA라는 데이터가 들어온 것을 볼 수 있다.
이 데이터가 변환 및 압축과정을 거쳐 최종적으로 암호화되는 과정을 인코딩이라고 한다.
그리고 이 인코딩의 반대 과정을 디코딩이라고 한다.
응용 계층에서 표현 계층까지의 데이터 흐름을 조금 더 쉽게 설명해보자.
우리가 편지를 보낼 때 가장 먼저 하는 일이 무엇일까?
바로 편지지를 선택하고 편지 내용을 작성하는 것이 아닐까?
이게 바로 응용 계층에서 하는 일이다.
편지지 선택 = 어플리케이션 선택
편지 내용 작성 = 어플리케이션 실행 및 활동
이제 이 편지를 외국인 친구에게 보낸다고 가정해보자.
편지를 받은 친구도 이해할 수 있도록 그 나라 언어로 번역을 하고 편지지를 잘 접어 봉투에 넣는다.
편지를 나와 친구만 알아볼 수 있도록 암호화를 할 수도 있다.
이것이 바로 표현 계층에서 일어나는 일(변환, 압축, 암호화)이다.
이제 편지(데이터)를 보낼 준비가 다 되었으니 5계층으로 넘어가보자.
세션 계층은 네트워크상 양쪽 연결을 관리하고 연결을 지속시켜주는 계층이다.
쉽게 말하자면 통신을 함에 있어서 대문 역할을 한다.
그리고 이 계층에는 세션 종료, 유지, 중단 시 복구의 기능이 있다.
이쯤에서 세션이 무엇인지 잠깐 설명해보면,
방문자가 웹 서버에 접속해 있는 상태를 하나의 단위로 보고 이를 세션이라고 한다.
현재 웹 서버에 접속해 있다면 세션이 연결된 상태이다.
세션에 대해 더 자세한 내용은 다음에 다루기로 한다.
세션 계층은 데이터가 오고 가는 흐름 내에서 동기화 지점을 제공하기도 한다.
동기화 지점은 쉽게 말하면 체크 포인트이다.
다음 예제에서 좀 더 자세히 알아보자.
5MB마다 체크포인트가 설정 되어있는 컴퓨터에서 서버로 50MB의 데이터를 전송한다.
33MB 정도 전송했는데 이게 무슨 일일까? 전송이 끊겨 버렸다.
이 때 전송되고 있던 데이터는 어떻게 되었을까? 다시 처음부터 전송해야 할까?
다행히 세션 계층이 체크포인트를 지정해주었기 때문에 우리는 데이터를 처음부터 전송하지 않아도 된다.
이것이 세션 계층의 중요한 기능 중 하나이다.
이제 데이터는 전송 계층으로 내려온다.
우리는 앞서 7계층에서 우리가 사용하고 있는 애플리케이션들이 응용 계층이라고 배웠다.
데이터의 여행은 최종적으로 상대 컴퓨터의 7계층에 도달하는 것이다.
그럼 지금, 우리의 컴퓨터나 핸드폰을 확인해보자.
달거북씨처럼 10개 이상의 애플리케이션이 실행중일 수도 있고 수십 개가 깔려 있을 수도 있다.
이처럼 수두룩 빽빽한 애플리케이션의 숲에서,
데이터는 어떻게 자신이 가야할 곳을 정확히 찾아갈 수 있을까?
그건 바로 데이터가 가지고 있는 일종의 지도, 바로 포트번호 덕분이다.
전송 계층에서는 데이터가 상대 응용 계층을 정확하게 찾아갈 수 있도록 포트번호를 데이터에 달아준다.
데이터는 목적지의 상대 컴퓨터에서 이 포트번호를 확인하고 자신이 가야 할 애플리케이션을 찾아간다.
위의 그림을 보자.
데이터의 포트번호는 5223이다.
이 데이터는 어떤 애플리케이션으로 가게 될까?
맞다. 같은 포트번호를 가진 카카오톡을 찾아가게 된다.
즉, 포트번호는 보내는 이, 받는 이에게 할당되는 번호로써,
같은 주소 내에서 정확히 받는 사람에게 전달되도록 하는 지표이다.
포트번호는 6만 개 이상의 번호가 있고, 번호에 따라 웰노운 포트, 등록된 포트, 동적포트로 나눠진다.
강제는 아니지만 전 세계 모든 컴퓨터가 위의 표와 같은 분류에 따른 포트번호를 사용하도록 권고되고 있다.
전송계층의 또 다른 역할은 패킷 전송 제어 역할이 있다.
패킷이 전송 과정에서 아무 문제 없이 제대로 수신지의 컴퓨터에 도착할 수 있도록 패킷 전송을 제어하는 것이다.
핵심 프로토콜로는 TCP와 UDP가 있다.
패킷이란, 인터넷 내에서 데이터를 보내기 위한 경로배정(라우팅)을 효율적으로 하기 위해 데이터를 여러 개의 조각들로 나누어 전송을 하는데, 이 조각을 패킷이라고 한다.
TCP와 UDP는 택배에 비유하면 쉽게 이해가 가능하다.
쿠팡처럼 수신지에 그냥 물건을 두고 가는 것이 UDP이고,
택배를 전달할 때 수신지에 받는 사람이 있는지 물건이 맞는지 등 정보를 확인하는 과정을 거쳐 전달하는 것이 TCP이다.
즉, TCP는 통신할 컴퓨터끼리 ‘보냈습니다’, ‘도착했습니다’ 라고 서로 확인 메시지를 보내면서 여러 번의 확인 과정(3-way-handshake)을 거쳐 데이터를 정확하게 전달한다. 그래서 UDP보다는 속도가 느리다. 반대로 UDP는 데이터를 보내면 그것으로 끝이므로 데이터를 보다 빠르게 전달할 수 있지만 그 만큼 신뢰성은 보장할 수 없다.
전송계층이 세 번째 역할은 '세그멘테이션'이다. 단어 뜻 그대로 분할하는 역할을 한다.
예를 들어 우리가 수산 시장에서 참치를 구매했다고 가정해보자.
참치는 너무 커서 한 번에 운반하기가 어렵다.
따라서 우리는 참치를 쉽고 편리하게 가져가기 위해서 분할을 해야한다.
이 과정을 세그멘테이션이라고 한다.
그리고 나눈 것들을 세그먼트라고 한다.
그럼 왜 세그멘테이션을 해야 할까?
예를 들어 전달 받은 상위 계층 데이터를 그대로 전달한다고 해보자.
100MB 동영상을 재생하기 위해서 데이터를 통째로 전달할 경우, 데이터를 모두 전달받아야 재생이 가능하다.
반면 세그멘테이션을 통해 패킷을 분할해서 전달하면 어떻게 될까?
데이터를 모두 받을 때까지 기다리지 않아도 전달받은 데이터부터 우선 재생이 가능해진다.
즉, 다운로드 받으면서도 우리는 영상을 볼 수 있게 된다.
세그멘테이션을 해서 얻는 또 다른 장점은 데이터 전송이 중간에 끊겼을 때 데이터 손실률이 적다는 점이다.
데이터를 통으로 전달하다가 전송이 끊기면 데이터가 통째로 손실되지만,
분할되어 있는 데이터는 일부만 손실되기 때문에 손실률이 적다.
지금까지 7계층에서 4계층까지 내려오는 동안 우리는 데이터가 어떻게 가공되고 어떻게 가는지에 대해 알아봤다.
3계층부터는 실질적으로 데이터가 어떻게 전달되는지를 공부할 수 있다.
네트워크 계층은 실질적으로 보내고 싶은 곳에 데이터를 전달하는 역할을 한다.
우선 라우팅을 한다.
라우팅은 쉽게 말하면 데이터를 보낼 최적의 경로를 찾는 것이라고 할 수 있다.
예를 들어, 우리가 어떤 목적지를 갈 때 내비로 최적의 길을 찾아가듯이, 3계층에선 라우터가 그 역할을 한다.
위 그림처럼 내 컴퓨터에서 상대방의 컴퓨터까지 최적의 경로를 찾는 모습을 볼 수 있다.
그리고 그 경로를 따라 데이터를 보내는 것을 포워딩이라고 한다.
이 때, 라우팅과 포워딩을 하는 라우터는 컴퓨터의 IP 주소를 이용해 데이터를 전달한다.
IP주소란, 간단히 설명하면 컴퓨터 네트워크 상에서 서로를 인식하고 통신하기 위해 사용되는 특수한 번호이다.
지금까지 많은 단계를 거쳐 마침내 데이터를 보낼 '장소' 즉, 컴퓨터가 어디에 있는지까지 파악했다.
하지만 위치만 파악했을 뿐 정확한 상세주소를 모르는 상태이다.
데이터링크계층에서는 바로 이 상세주소를 MAC 주소를 통해 파악한다.
MAC 주소란 일종의 컴퓨터 고유의 번지수이다.
우리집에 모두 각자 주소가 있듯이 컴퓨터 역시 본인만이 가지고 있는 주소가 있고,
이 주소를 2계층에서 분석하여 데이터가 최종적으로 어느 곳으로 가는지 파악한다.
2계층은 데이터를 보낼 때 MAC 주소를 데이터에 붙여 데이터의 출처를 다른 PC에서도 알 수 있도록 한다.
그리고 그 데이터는 스위치라는 2계층 통신장비에 의해 분석된다.
2, 3계층의 흐름을 같이 설명하면 이해하기가 쉽다.
A 컴퓨터에서 B 컴퓨터로 데이터를 보내려고 한다.
이 데이터에는 A 컴퓨터와 B 컴퓨터의 IP주소가 모두 적혀 있지만,
도착지의 MAC 주소가 아닌 가장 가까운 라우터의 MAC 주소가 도착지로 적혀있다.
따라서 A에서 스위치로 데이터를 보내면,
스위치에서는 MAC 주소를 살펴보고 해당하는 가장 가까운 라우터로 데이터를 보낸다.
라우터는 데이터 도착지에 대한 IP 주소를 체크하여 라우팅 테이블을 통해 라우팅을 시키고,
데이터는 B 컴퓨터 네트워크 근처의 라우터에 도착하게 된다.
B 컴퓨터 근처의 라우터는 MAC 주소 테이블을 통해 해당 데이터의 도착지 MAC 주소를 파악하고,
MAC 주소를 도착지의 MAC 주소로 업데이트 하여 스위치로 다시 데이터를 전달한다.
데이터를 전달받은 스위치는 MAC 주소를 파악하여 B 컴퓨터로 데이터를 정확하게 보낸다.
OSI 7계층의 마지막, 1계층은 물리계층이라 불리며 최종적으로 데이터가 도착하는 계층이다.
1계층은 도착한 데이터를 컴퓨터가 이해할 수 있는 이진수의 전자신호로 바뀌고,
이 전기 신호를 다시 아날로그 신호로 바꿔줌으로써 케이블로 이동할 수 있도록 한다.
전체적인 흐름을 짚어보자.
7계층에서 1계층까지 각 계층마다 헤더를 붙여 1계층까지 내려준다. (헤더는 각 계층별로 처리한 데이터의 결과물이다)
다른 컴퓨터에 도착한 데이터는 각 계층마다 하나씩 까져서 최종적으로 애플리케이션에 도착하게 된다.