달거북씨 첫 자바수업 그 마지막 정리
프로그램
아직 실행되지 않은 상태
소스코드로 잘 짜여진 틀
프로세스
실행중인 프로그램으로 자원과 쓰레드로 구성되어 있다.
1. 쓰레드
프로세스 내에서 실제 작업처리 경로
모든 프로세스는 최소 하나의 쓰레드를 가지고 있다.
단일 쓰레드
1) 하나의 작업에 문제가 발생하더라도 다른 작업에는 영향을 끼치지 않는다.
2) 설계도가 멀티 쓰레드에 비해 단순하다.
3) 처리경로가 하나로 직렬적이기 때문에 동시에 많은 양을 처리하기 힘들다.
멀티 쓰레드
1) 여러 개의 쓰레드(처리경로)를 가질 수 있다.
2) 한 개의 처리 경로를 여러 개로 나누어 동시 작업이 가능해진다.
3) 대부분의 프로그램이 멀티 쓰레드로 작성되어 있다.
4) 처리량 증가, 효율성 증가, 처리 비용 감소의 장점이 있다.
5) 프로그래밍을 할 대 고려해야 할 사항들이 많기 때문에 설계 방식이 굉장히 어렵다.
6) 하나의 쓰레드 문제 발생 시 모든 쓰레드에 문제가 발생하게 된다.
단일 쓰레드와 멀티 쓰레드 비교
하나의 새로운 프로세스를 생성하는 것보다(→ 단일 쓰레드) 하나의 새로운 쓰레드를 생성하는 것이 더 적은 비용이 든다(→ 멀티 쓰레드) >> 하나의 프로세스를 가지고 더 많은 사용자의 요청을 처리할 수 있게 된다.
ex. 카카오톡에서 파일을 전송했을 때,
- 단일 쓰레드일 경우 파일 전송이 완료될 때까지 다음 작업을 수행하지 않는다.
- 멀티 쓰레드일 경우 파일 전송이 완료되는 동안 다음 작업도 동시에 수행 가능하다.
쓰레드의 생성방법 2가지
1) Thread 클래스 상속
class MyThread extends Thread{
public void run(){
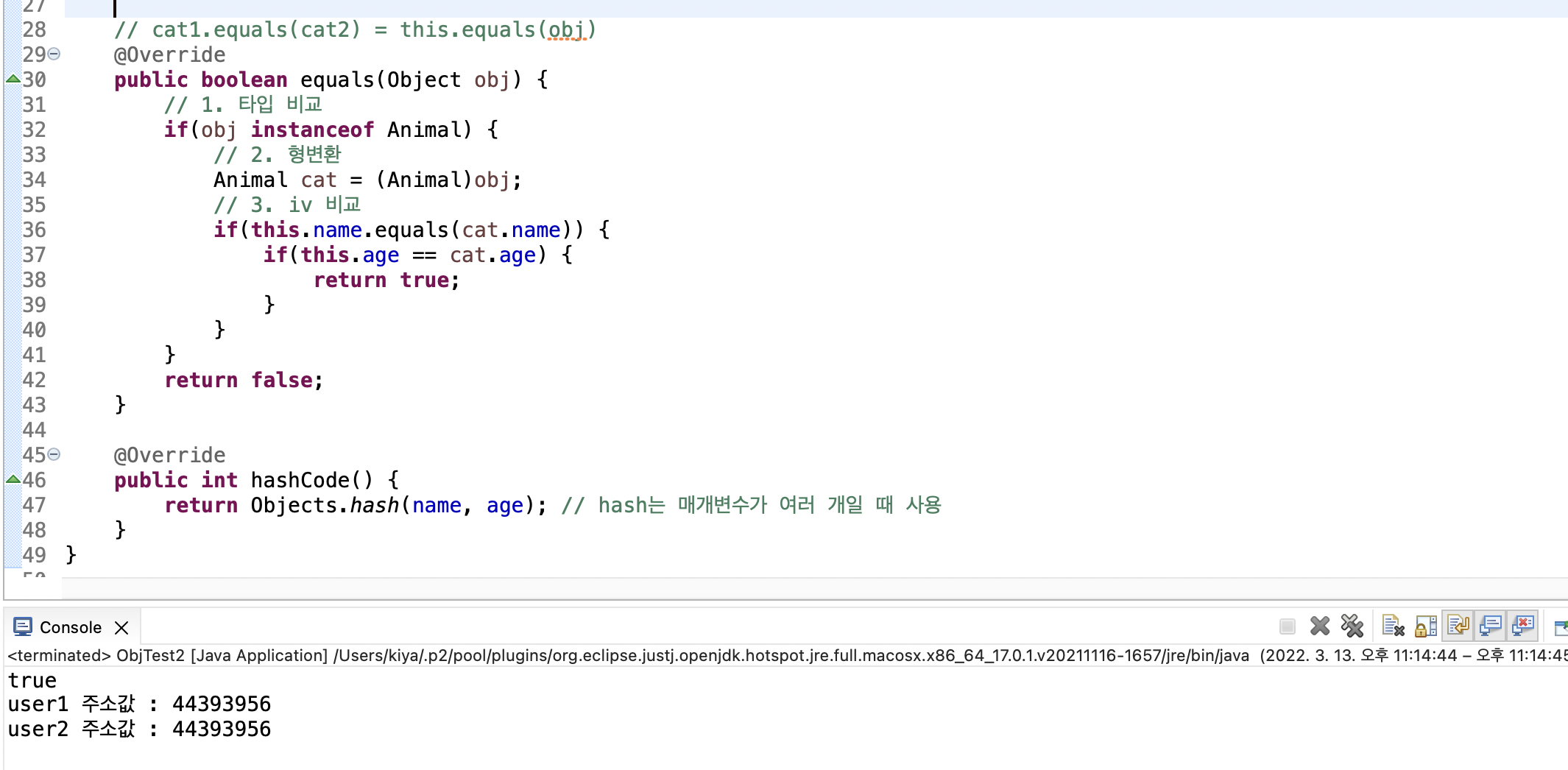
// 쓰레드 작업 내용
}
}
MyThread t = new MyThread();
t.start();① Thread를 상속받은 후 run() 메소드를 오버라이딩한다.
② 사용 시 쓰레드의 객체를 생성하고, start() 메소드를 통해 쓰레드를 실행한다.
2) Runnable 인터페이스 지정 후 Thread에 넘겨주기
class MyRunnable implements Runnable{
public void run(){
// 쓰레드 작업 내용
}
}
MyRunnable r = new MyRunnable();
Thread t = Thread(r); // Thread(Runnable r)
t.start();① Runnable 인터페이스를 지정받은 클래스에 추상메소드 run()을 구현한다.
② 사용시 Runnable 인터페이스를 구현한 클래스의 객체를 생성한다.
③ Thread 클래스 객체를 생성하여 Thread의 생성자의 매개변수에 ②에서 구현한 객체를 넘겨준다.
> 즉, 외부에서 매개변수로 받은 Runnable 객체로 run()이라는 메소드의 구현체를 받아옴
④ Thread의 객체로 start() 메소드를 호출하여 쓰레드를 실행한다.
> 외부에서 제공한 run()을 Thread에서 호출
메소드
- run() : main(){작업내용}을 적는 것과 같이 run()에 쓰레드의 작업 내용을 작성한다.
- start() : JVM에 쓰레드를 스케줄링 해주는 역할로 호출해야 쓰레드가 작업을 시작한다. 즉, start()를 하면 실행 준비
상태가 되는 것이기 때문에 언제 실행될 지는 OS 스케줄러가 실행순서를 결정한다.
- join() : 특정 쓰레드 종료 시까지 다른 쓰레드들을 멈추게 한다.
- sleep() : 현재 쓰레드를 지정된 시간동안 흐름을 멈추게 한다.
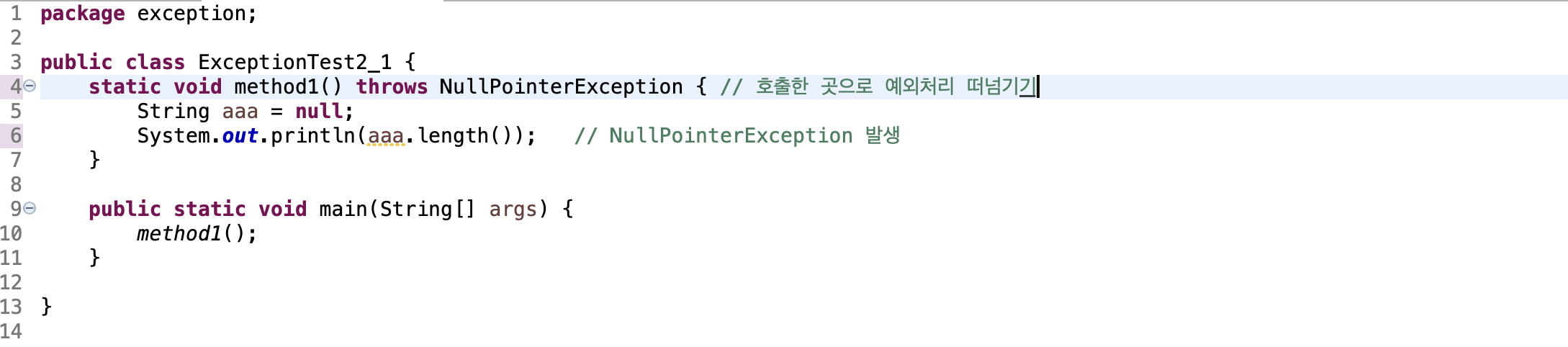
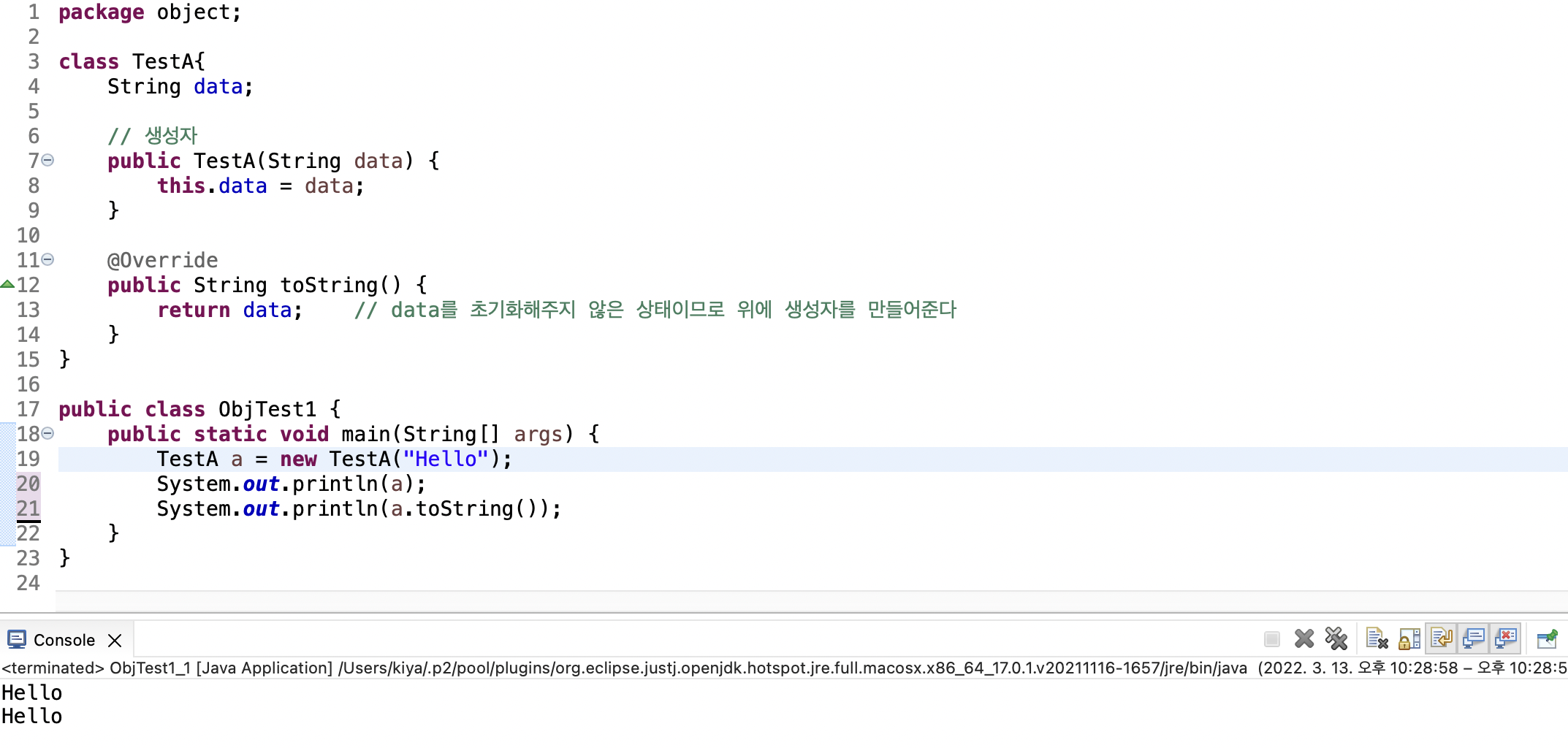
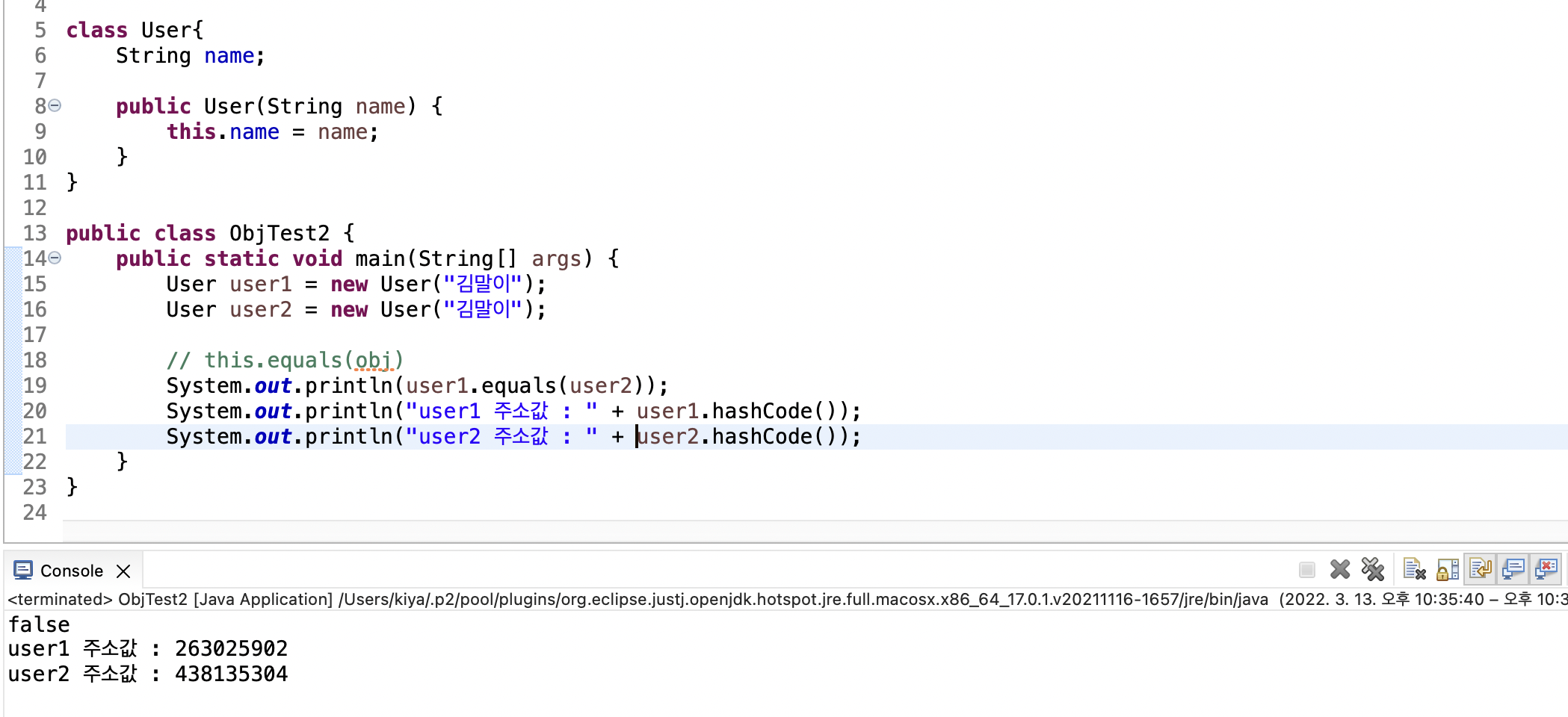
예제



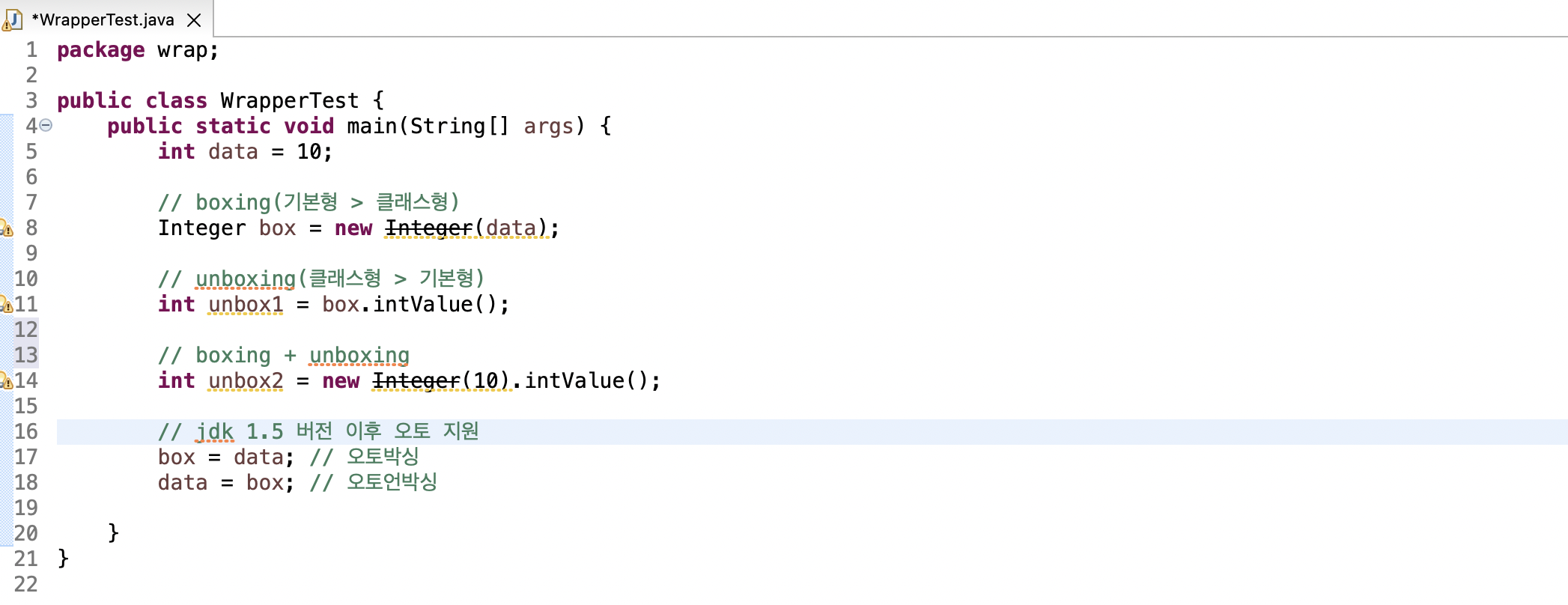
2. 파일 입출력
Writer(입력)
FileWriter > BufferedWriter > 파일에 입력
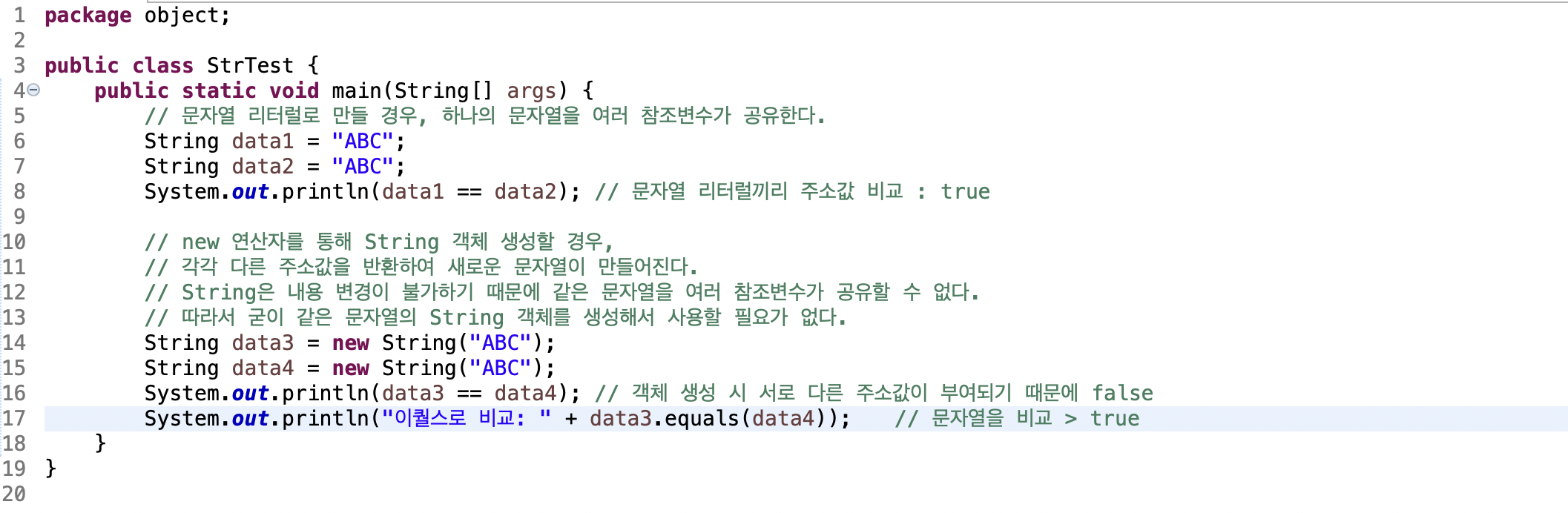
FileWriter fw = new FileWriter();- FileWriter : 경로에 있는 파일 가져오기
* 파일이 없는 경우에는 그 이름대로 파일을 생성
* 하지만 경로가 이상한 경우에는 예외가 발생(IOException)
- new FileWriter("파일경로") : 덮어쓰기 모드
- new FileWriter("파일경로", true) : 추가모드(true) 또는 덮어쓰기(false)도 가능
BufferedWriter bw = new BufferedWriter();- bw.write("문자열") : 버퍼에 문자열 쓰기
- bw.close() : 파일에 적용
버퍼에 있는 데이터들을 파일에 써주면서 버퍼 닫기
Reader(출력)
FileReader > BufferedReader > 파일에서 읽어와 출력
FileReader fr = new FileReader();- FileReader : 경로에 있는 파일 가져오기(읽기 위해)
* 파일이 없으면 예외발생(IOException)
- new FileReader("파일경로")
BufferedReader br = new BufferedReader();- BufferedReader : 버퍼를 이용해서 파일 읽기
- br.readLine() : 파일에 있는 니용 판 줄 읽어오기
* 파일이 끝이라면 null을 반환
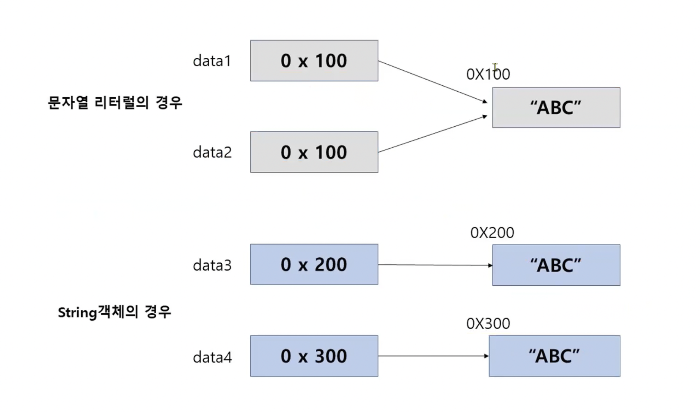
버퍼(buffer)
1) 데이터를 한 곳에서 다른 한 곳으로 전송하는 동안 일시적으로 그 데이터를 보관하는 임시 메모리 영역
2) 외부 파일의 입력소스를 직접 입출력하는 것보다 버퍼를 이용하는 쪽이 훨씬 빠르고 작업의 효율이 높아진다.
> 버퍼를 사용하여 외부의 파일에 데이터를 입력할 대 데이터를 모아 문자로 묶어서 한 번에 전송하게 된다.
> 또한 외부의 파일을 읽어올 때(출력), 데이터를 읽어와 버퍼에 저장한 후 읽어온다.
예제


실습






'이론 > 자바 기초' 카테고리의 다른 글
| java 그게 뭐야? 17.HashSet, Iterator, HashMap, 빠른 for문 (0) | 2022.03.20 |
|---|---|
| JAVA 그게 뭐야? 16. 컬렉션프레임워크, ArrayList, <>Generic제네릭 (0) | 2022.03.19 |
| JAVA 그게 뭐야? 15. 예외처리, API, Object클래스, String클래스, Wrapper클래스 (0) | 2022.03.14 |
| JAVA 그게 뭐야? 14. 접근 권한 제어자, 추상메소드, 캡슐화, 익명클래스 (0) | 2022.03.12 |
| JAVA 그게 뭐야? 13. 상속2 (0) | 2022.03.06 |